04/11/2025
Tóm tắt
Nghiên cứu này nhằm khắc phục hạn chế của ảnh vệ tinh truyền thống trong nhận dạng loài rừng ngập mặn, khi các loài có phổ phản xạ tương đồng và bị ảnh hưởng bởi mây, nước đục và nhiễu cảm biến. Phương pháp đề xuất tích hợp biểu diễn phổ sâu (Deep Spectral Embedding) biểu diễn đặc trưng 64 chiều được học từ dữ liệu vệ tinh đa nguồn theo chuỗi thời gian - với các thuật toán phân cụm không giám sát K-Means để phân loại loài thực vật rừng ngập mặn. Thực nghiệm được triển khai tại Vườn quốc gia Xuân Thủy (tỉnh Ninh Bình), khu Ramsar đầu tiên của Việt Nam, nơi có hệ sinh thái ngập mặn phát triển điển hình. Kết quả cho thấy, dữ liệu phân biệt hiệu quả các loài đặc hữu như mắm, đước vòi, trang với độ chính xác 86.7%, vượt trội so với các nguồn dữ liệu ảnh viễn thám truyền thống. Nghiên cứu khẳng định tiềm năng của embedding học sâu trong bản đồ hóa hệ sinh thái và nhận dạng loài rừng ngập mặn ở quy mô chi tiết.
Từ khóa: Biểu diễn phổ sâu, phân cụm K-Means, rừng ngập mặn, Vườn quốc gia Xuân Thủy, nhận dạng loài.
Ngày nhận bài: 9/9/2025; Ngày sửa chữa: 5/10/2025; Ngày duyệt đăng: 20/10/2025.
Application of Deep Spectral Embedding and Clustering Algorithms for Mangrove Species Identification in Xuan Thuy National Park
ABSTRACT
This study aims to overcome the limitations of conventional satellite imagery in mangrove species identification, where spectral signatures are often similar among species and affected by clouds, turbid water, and sensor noise. The proposed approach integrates Deep Spectral Embedding, a 64-dimensional feature representation learned from multi-source satellite time series data, with an unsupervised K-Means clustering algorithm to classify mangrove species. Experiments were conducted in Xuan Thuy National Park, the first Ramsar site in Vietnam, which hosts a representative mangrove ecosystem. The results demonstrate that the embedding effectively discriminates endemic species such as Rhizophora, Avicennia, and Sonneratia, achieving an overall accuracy of 86.7%, outperforming traditional remote sensing datasets. This study confirms the potential of deep spectral embeddings for ecosystem mapping and fine-scale species identification in mangrove forests.
Keywords: Deep Spectral Embedding, clustering; K-Mean, mangrove species, Xuân Thủy National Park; multi-source satellite data.
JEL Classifications: Q51, Q52, Q53.
1. Giới thiệu
Rừng ngập mặn (RNM) là một trong những hệ sinh thái ven biển có giá trị sinh thái cao, đóng vai trò quan trọng trong bảo vệ bờ biển, giảm thiểu thiên tai, lưu trữ carbon và duy trì đa dạng sinh học (Alongi, 2014). Tại Việt Nam, Vườn quốc gia Xuân Thủy (tỉnh Ninh Bình) không chỉ là khu Ramsar đầu tiên được công nhận ở Đông Nam Á mà còn là nơi tập trung nhiều loài thực vật ngập mặn đặc hữu và có giá trị bảo tồn cao. Tuy nhiên, áp lực từ nuôi trồng thủy sản, xói lở bờ biển và biến đổi khí hậu đang đe dọa nghiêm trọng cấu trúc và thành phần loài của hệ sinh thái này (Friess, 2019). Vì vậy, việc nhận dạng chính xác các loài thực vật trong hệ sinh thái rừng ngập mặn là điều cấp thiết để phục vụ quản lý, phục hồi sinh thái và hạch toán vốn tự nhiên.
Các nghiên cứu lập bản đồ rừng ngập mặn trước đây chủ yếu dựa vào chỉ số thực vật phổ như NDVI, EVI hoặc các phương pháp phân loại có giám sát (supervised classification) từ ảnh Landsat, Sentinel-2, SPOT và UAV (Kuenzer, 2011; Maurya, 2021). Các chỉ số này phản ánh sức khỏe và mật độ thảm thực vật, nhưng lại thiếu khả năng phân biệt các loài có đặc tính sinh lý và cấu trúc lá tương tự nhau, dẫn tới sai số lớn ở cấp độ loài (Giri et al., 2016; Pham & Yoshino, 2017). Bên cạnh đó, dữ liệu quang học ở vùng ven biển thường chịu ảnh hưởng mạnh của mực nước thủy triều, độ mặn, bùn cát lơ lửng và độ ẩm đất, làm biến dạng đường cong phản xạ phổ, khiến hiệu suất phân loại bị giảm đáng kể (Tran, Reef & Zhu, 2022; Sun, 2024).
Để khắc phục các hạn chế trên, một số nghiên cứu đã thử nghiệm các kỹ thuật học máy nâng cao và học sâu như Random Forest, Support Vector Machine, Convolutional Neural Networks (CNN) hoặc Autoencoders nhằm cải thiện khả năng phân biệt loài rừng ngập mặn (Zhang, 2023; Behera, 2021). Tuy nhiên, hầu hết các phương pháp này vẫn phụ thuộc lớn vào dữ liệu huấn luyện gán nhãn, trong khi dữ liệu thực địa về loài tại các vùng ven biển như Việt Nam thường khan hiếm, tốn kém và khó thu thập.
Gần đây, xu hướng ứng dụng biểu diễn phổ sâu (Deep Spectral Embedding) đã được đề xuất như một giải pháp tiềm năng nhằm nén dữ liệu phổ đa chiều thành không gian đặc trưng thấp chiều nhưng vẫn giữ được các thông tin phi tuyến quan trọng về cấu trúc phổ – không gian (Yaseen, 2023; Guo, 2024). Phương pháp này giúp tách biệt các loài có phổ phản xạ tương đồng nhưng khác biệt tinh vi về hàm lượng diệp lục, cấu trúc mô lá hoặc mức độ ngập mặn (Boykis,2023). Tuy nhiên, cho đến nay, chưa có nghiên cứu nào áp dụng phương pháp này để nhận dạng loài rừng ngập mặn tại Việt Nam, đặc biệt ở các khu Ramsar như Vườn quốc gia Xuân Thủy, nơi có tính đa dạng sinh học cao nhưng điều kiện phản xạ phổ phức tạp do thủy văn ảnh hưởng.
Tính mới của nghiên cứu này nằm ở việc đề xuất ứng dụng Deep Spectral Embedding, một phương pháp học đặc trưng phổ sâu không giám sát, kết hợp với thuật toán phân cụm (K-means và DBSCAN) để phân loại loài rừng ngập mặn tại Vườn quốc gia Xuân Thủy. Khác với các nghiên cứu truyền thống, phương pháp này không phụ thuộc hoàn toàn vào dữ liệu huấn luyện gán nhãn và có khả năng nhận dạng tốt các loài có phổ phản xạ tương đồng nhưng khác biệt tinh vi trong cấu trúc tế bào lá và chất diệp lục. Đồng thời, nghiên cứu xây dựng một quy trình tự động gồm: xử lý ảnh Sentinel-2, giảm chiều dữ liệu phổ, nhúng phổ sâu (embedding), phân cụm loài và kiểm chứng bằng dữ liệu thực địa.
Bài viết tập trung giải quyết ba nội dung chính: (i) phát triển quy trình Deep Spectral Embedding cho dữ liệu viễn thám rừng ngập mặn; (ii) đánh giá hiệu quả của thuật toán phân cụm trong nhận dạng loài; (iii) phân tích tiềm năng ứng dụng trong giám sát và bảo tồn hệ sinh thái. Mục tiêu cuối cùng là xây dựng một công cụ nhận dạng loài hiệu quả, ít phụ thuộc dữ liệu gán nhãn, nhằm hỗ trợ quản lý và quy hoạch bảo tồn tại Xuân Thủy.
2. Đối tượng và phương pháp nghiên cứu
2.1. Cơ sở lý thuyết và khung nghiên cứu
2.1.1. Hệ sinh thái rừng ngập mặn và yêu cầu phân loại tới cấp loài
Rừng ngập mặn là một trong những hệ sinh thái có năng suất sinh học cao nhất trên Trái Đất, đóng vai trò phòng hộ bờ biển, hấp thụ carbon xanh (blue carbon) và duy trì đa dạng sinh học vùng cửa sông – ven biển (Alongi, 2018). Việt Nam hiện có khoảng 150.000 ha rừng ngập mặn, tập trung chủ yếu ở Đồng bằng sông Cửu Long, Đồng bằng sông Hồng và ven biển miền Trung (Nguyen, 2021), trong đó Vườn quốc gia Xuân Thủy là khu Ramsar đầu tiên và nơi sinh cảnh của nhiều loài cây ngập mặn bản địa và phục hồi (Truong,2021).
Mặc dù nhiều nghiên cứu đã lập bản đồ rừng ngập mặn, phần lớn chỉ dừng ở mức phân loại lớp phủ hoặc nhóm thực vật (mặn, lợ, hỗn giao), chưa đạt đến cấp độ loài (species-level mapping) (Behera, 2021; Tran, 2022). Việc nhận dạng tới cấp loài là yêu cầu thiết yếu để đánh giá cấu trúc quần xã, trữ lượng sinh khối và carbon, theo dõi xâm lấn sinh học và thiết kế phục hồi sinh thái (Friess et al., 2019). Trong hơn một thập kỷ qua, lập bản đồ rừng ngập mặn chủ yếu dựa trên ba nhóm phương pháp: (i) sử dụng các chỉ số phổ thực vật như NDVI, EVI, NDWI từ ảnh Landsat và Sentinel-2 để xác định vùng phủ thực vật ngập mặn (Kuenzer et al., 2011); (ii) phân loại có giám sát bằng các thuật toán như SVM, Random Forest, CART (Pham & Yoshino, 2017; Pham, 2019); và (iii) ứng dụng ảnh UAV kết hợp mô hình học sâu (CNN, ResNet, U-Net) nhằm tăng chi tiết không gian và độ chính xác (Hao, 2023). Tuy nhiên, các phương pháp này phần lớn chỉ dừng lại ở việc phân biệt rừng ngập mặn với các loại đất ngập nước khác chứ chưa đạt được phân cấp chi tiết tới mức loài (species-level) một yêu cầu quan trọng để đánh giá đa dạng sinh học, sinh khối carbon và khả năng phục hồi hệ sinh thái. Lý do là vì phổ phản xạ của nhiều loài rừng ngập mặn gần như trùng lặp ở các dải xanh - đỏ - cận hồng ngoại, khiến NDVI, EVI hoặc phân loại supervised khó phân biệt giữa các loài có cấu trúc tán lá tương tự (Tran, Reef & Zhu, 2022). Trong khi đó, ảnh vệ tinh bị ảnh hưởng mạnh bởi thủy triều, độ ẩm đất, trầm tích lơ lửng, hiện tượng ngập mặn theo mùa và nền bùn ven biển, làm suy giảm tín hiệu quang phổ và gây sai số khi phân loại. Bên cạnh đó, các mô hình học máy có giám sát (supervised learning) đòi hỏi dữ liệu gán nhãn lớn và chính xác từ thực địa, trong khi dữ liệu loài rừng ngập mặn tại Xuân Thủy và nhiều khu vực Việt Nam còn rất hạn chế, phân bố loài không đồng đều, thậm chí sai lệch do biến động theo thủy triều hoặc diện tích bãi bồi mới hình thành.
Do vậy, tồn tại một khoảng trống khoa học quan trọng: chưa có phương pháp hiệu quả nào cho phép phân loại rừng ngập mặn tới cấp loài trên dữ liệu vệ tinh quang học, đặc biệt trong điều kiện pha trộn loài và nhiễu động thủy văn đặc thù vùng cửa sông ven biển Việt Nam. Điều này đặt ra nhu cầu cấp thiết về các phương pháp mới, có khả năng khai thác sâu các đặc trưng phổ – không gian phức tạp, ít phụ thuộc dữ liệu gán nhãn và thích ứng với điều kiện thủy triều động.
2.1.2. Biểu diễn phổ sâu (Deep Spectral Embedding)
Deep Spectral Embedding là một hướng tiếp cận mới trong học biểu diễn (representation learning), trong đó mỗi điểm ảnh không còn được mô tả bằng các giá trị phản xạ phổ đơn lẻ tại các kênh đỏ, xanh, NIR hay chỉ số NDVI, mà được ánh xạ thành một véc-tơ có từ 64 đến 256 chiều trong không gian đặc trưng ngữ nghĩa (spectral–semantic space). Các véc-tơ này được học từ hàng triệu chuỗi thời gian ảnh vệ tinh đa nguồn (Sentinel-2, Landsat, Sentinel-1 SAR, LiDAR, DEM…), thông qua các mô hình học sâu tự giám sát như Autoencoder, Contrastive Learning hoặc Transformer (Tran, Reef & Zhu, 2022; Guo, 2024). Phương pháp này cho phép mô hình tự tìm kiếm các cấu trúc ẩn trong dữ liệu phổ–thời gian, thay vì phụ thuộc hoàn toàn vào dữ liệu gán nhãn như cách phân loại truyền thống. Một ví dụ điển hình là bộ dữ liệu AlphaEarth v2 – Google Earth Engine Satellite Embedding, trong đó mỗi pixel 10 m được biểu diễn bằng một véc-tơ 64 chiều đã được: (i) chuẩn hóa trên không gian cầu đơn vị, (ii) hiệu chỉnh mây, cảm biến và biến thiên thời gian, và (iii) đồng bộ hóa giữa các hệ quy chiếu quang học – radar (c). Các véc-tơ embedding này không chỉ nắm giữ thông tin phổ, mà còn mã hóa các đặc trưng sinh thái sâu hơn, bao gồm:
Nhờ khả năng tổng hợp đồng thời đặc trưng quang học - radar - không gian - thời gian, embedding sâu có thể tách biệt các loài rừng ngập mặn có phổ phản xạ gần như giống nhau nhưng khác nhau về sinh lý lá, cấu trúc tán, chu kỳ sinh trưởng và khả năng thích nghi mặn. Trong không gian embedding này, các loài sẽ hình thành các cụm (clusters) rõ ràng hơn theo đặc tính sinh thái - cấu trúc, hỗ trợ hiệu quả cho các thuật toán phân cụm (k-means, spectral clustering, DBSCAN) hoặc phân loại bán giám sát (Willett, 2016). Nhờ vậy, Deep Spectral Embedding cho phép trích xuất thông tin sinh thái ở mức cao hơn mà không cần lượng lớn mẫu huấn luyện, tạo ra một giải pháp bán tự động - ít dữ liệu thực địa - nhưng vẫn đảm bảo độ tin cậy, rất phù hợp cho các vùng ven biển như Xuân Thủy, nơi công tác điều tra loài còn nhiều hạn chế. Từ những phân tích trên có thể thấy rằng, các phương pháp phân loại dựa trên phổ quang học truyền thống, mặc dù đã được ứng dụng rộng rãi, vẫn tồn tại những hạn chế cố hữu như phụ thuộc nhiều vào dữ liệu gán nhãn, khó nhận diện các loài có phổ tương đồng và thiếu khả năng khái quát khi áp dụng trên những khu vực khác nhau. Điều này đặt ra yêu cầu cần có một cách tiếp cận mới, linh hoạt hơn và giảm sự phụ thuộc vào dữ liệu thực chứng.
Trong bối cảnh đó, Deep Spectral Embedding được xem như một hướng tiếp cận đầy tiềm năng. Nhờ khả năng học biểu diễn kết hợp phổ - không gian ở mức trừu tượng cao, phương pháp này không chỉ giảm nhu cầu về dữ liệu thực địa mà còn cải thiện độ chính xác trong phân tách loài, đặc biệt tại các hệ sinh thái phức tạp như rừng ngập mặn. Đây là lợi thế đáng kể trong những khu vực thiếu dữ liệu khảo sát như Vườn quốc gia Xuân Thủy.
Trên cơ sở đó, nghiên cứu này xây dựng một khung phương pháp tổng thể, nhằm khai thác ưu thế của Deep Spectral Embedding trong phân loại đa loài rừng ngập mặn và đánh giá đa dạng sinh học. Khung nghiên cứu gồm ba hợp phần chính: (1) Tiền xử lý và chuẩn hóa dữ liệu embedding ảnh vệ tinh; (2) Ánh xạ không gian đặc trưng và phân cụm trong không gian Deep Spectral Embedding; (3) Đánh giá, trực quan hóa và phân tích đa dạng sinh học
2.2. Phạm vi và khu vực nghiên cứu
Khu vực nghiên cứu là Vườn quốc gia Xuân Thủy, nằm tại cửa sông Ba Lạt - nơi sông Hồng đổ ra biển Đông, thuộc xã Giao Thủy, tỉnh Ninh Bình (20°10'-20°20' N; 106°20'-106°32' E). Đây là khu Ramsar đầu tiên của Việt Nam với diện tích khoảng 15.000 ha, bao gồm rừng ngập mặn tự nhiên, rừng phục hồi, bãi triều, đầm nuôi thủy sản và bãi bồi mới (Tue, 2012).
Khu vực chịu ảnh hưởng mạnh của thủy triều nhật triều không đều (biên độ 1,5–2,5 m), biến động độ mặn và lượng phù sa từ sông Hồng, khiến tín hiệu phổ của thực vật dễ bị nhiễu do nước, bùn và trầm tích lơ lửng. Địa hình thấp và ngập theo chu kỳ thủy triều làm giảm độ ổn định của ảnh vệ tinh, gây khó khăn cho phân loại tới cấp loài bằng các phương pháp quang học truyền thống.
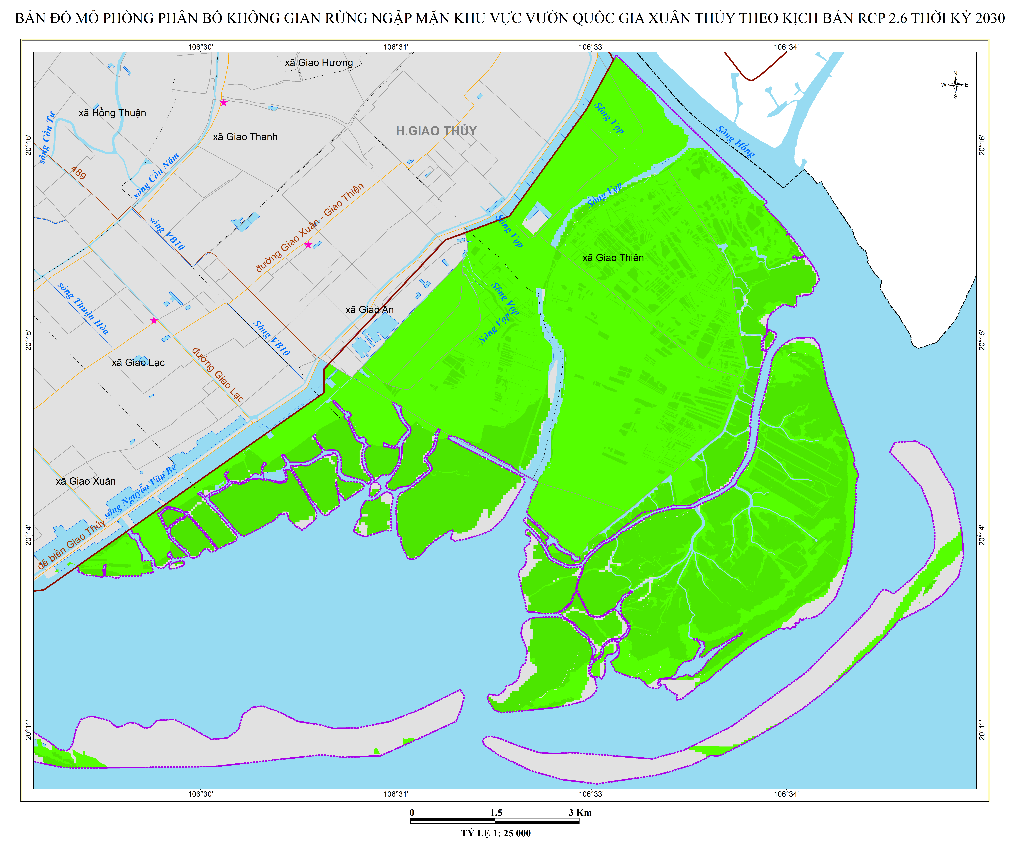
Hình 1. Phạm vi khu vực Vườn quốc gia Xuân Thủy (Nguồn: Viện Khoa học Khí tượng Thủy văn và Biến đổi khí hậu)
Với sự đa dạng sinh thái nhưng điều kiện quan sát phức tạp, Xuân Thủy là khu vực lý tưởng để kiểm chứng các phương pháp học biểu diễn sâu (Deep Spectral Embedding) nhằm phân biệt các loài rừng ngập mặn trong điều kiện thiếu dữ liệu gán nhãn thực địa.
2.3. Dữ liệu nghiên cứu
Nghiên cứu sử dụng hai nhóm dữ liệu chính: (i) dữ liệu embedding trích xuất từ ảnh vệ tinh; (ii) dữ liệu thực địa về thành phần loài rừng ngập mặn.
2.3.1. Dữ liệu embedding từ ảnh vệ tinh
Dữ liệu embedding được sử dụng trong nghiên cứu là các véc-tơ đặc trưng (feature vectors) có số chiều cố định (64 chiều), được sinh ra từ mô hình học sâu tiền huấn luyện trên tập ảnh vệ tinh đa thời gian và đa nguồn toàn cầu. Khác với ảnh quang học truyền thống chứa giá trị phản xạ phổ theo từng kênh, embedding biểu diễn mỗi pixel bằng một không gian đặc trưng trừu tượng hơn, phản ánh thông tin hình thái, cấu trúc thực vật, trạng thái sinh thái và biến động theo thời gian.
Nguồn dữ liệu được lấy từ bộ Google Earth Engine Satellite Image Embeddings (AlphaEarth), được xây dựng từ Sentinel-2 (10–20 m), kết hợp Landsat-8, độ cao SRTM, dữ liệu khí hậu, đạ dạng sinh học… Mô hình sinh embedding được huấn luyện theo cơ chế tự giám sát (self-supervised), cụ thể dự đoán thời gian hoặc vùng lân cận dựa trên chuỗi ảnh, nên véc-tơ cuối cùng không phụ thuộc kênh phổ đơn lẻ mà chứa thông tin ngữ cảnh không gian–thời gian của cảnh quan (Brown et al., 2025). Thông số kỹ thuật của ảnh được thống kê theo Bảng 1.
Bảng 1. Bảng Thông Số Kỹ Thuật Của Bộ Dataset Satellite Embeddings (AlphaEarth Foundations) Của Google
|
Thông Số |
Mô Tả |
|
Tên Dataset |
Satellite Embedding V1 (GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL) |
|
Nhà phát triển |
Google DeepMind (AlphaEarth Foundations) |
|
Độ phân giải |
10m x 10m mỗi pixel |
|
Chiều không gian Embedding |
64 chiều (64 bands: A00 đến A63) không mang ý nghĩa quang phổ mà là các trục nhúng |
|
Phạm vi thời gian |
Năm 2023 |
|
Phạm vi không gian |
Khu vực vườn quốc gia Xuân Thủy |
|
Kích thước tile |
Khoảng 163.840m x 163.840m mỗi ảnh |
|
Nguồn dữ liệu đầu vào |
- Ảnh quang học và nhiệt: Sentinel-2, Landsat |
|
Số lượng dữ liệu huấn luyện |
Hơn 3 tỷ frame ảnh từ hơn 5 triệu vị trí toàn cầu |
|
Kiến trúc mô hình |
Space Time Precision (STP) |
|
Giấy phép |
CC-BY 4.0 |
|
Nền tảng truy cập |
Google Earth Engine (miễn phí với tài khoản) |
|
Ảnh download |
|
Việc sử dụng embedding thay cho phổ ảnh truyền thống cho phép mô hình phân biệt tốt hơn giữa các loài có phổ phản xạ tương tự, do embedding tích hợp cả biến động theo mùa lá, cấu trúc tán, độ ẩm nền và tương quan không gian.
2.3.2. Dữ liệu thực địa
Bộ dữ liệu thực địa gồm 30 điểm khảo sát đại diện cho ba loài rừng ngập mặn chủ yếu trong khu vực Vườn quốc gia Xuân Thủy, tỉnh Ninh Bình. Các điểm được định vị bằng máy GPS cầm tay có sai số < 3 m và được thu thập trong mùa khô năm 2024. Các loài được ghi nhận gồm: Mắm biển - loài tiên phong phân bố vùng cửa sông; Đước vòi – loài chiếm ưu thế tại khu triều trung bình; Trang - loài đặc trưng vùng bãi triều thấp ven sông lớn.
Tập hợp dữ liệu này được dùng để đối chiếu kết quả phân cụm và nhận dạng loài từ dữ liệu embedding vệ tinh, hỗ trợ đánh giá độ chính xác của mô hình phân loại dựa trên học sâu.
Bảng 2. Các điểm khảo sát thực địa rừng ngập mặn tại Vườn quốc gia Xuân Thủy, tỉnh Ninh Bình năm 2024
|
FID |
X |
Y |
Loài |
|
FID |
X |
Y |
Loài |
|
1 |
20.242325 |
106.575110 |
Đước vòi |
|
16 |
20.235467 |
106.532742 |
Đước vòi |
|
2 |
20.241705 |
106.576494 |
Đước vòi |
|
17 |
20.234483 |
106.532219 |
Trang |
|
3 |
20.240846 |
106.578199 |
Đước vòi |
|
18 |
20.233920 |
106.531207 |
Mắm |
|
4 |
20.227849 |
106.574638 |
Trang |
|
19 |
20.232767 |
106.531874 |
Mắm |
|
5 |
20.227707 |
106.576411 |
Trang |
|
20 |
20.232134 |
106.527278 |
Trang |
|
6 |
20.226234 |
106.577940 |
Đước vòi |
|
21 |
20.231299 |
106.526697 |
Trang |
|
7 |
20.219032 |
106.568086 |
Đước vòi |
|
22 |
20.230367 |
106.520776 |
Trang |
|
8 |
20.217686 |
106.569432 |
Đước vòi |
|
23 |
20.236108 |
106.515819 |
Trang |
|
9 |
20.216286 |
106.570631 |
Đước vòi |
|
24 |
20.235327 |
106.516306 |
Trang |
|
10 |
20.218941 |
106.548864 |
Đước vòi |
|
25 |
20.234529 |
106.516912 |
Trang |
|
11 |
20.216698 |
106.548646 |
Trang |
|
26 |
20.230469 |
106.508413 |
Trang |
|
12 |
20.214287 |
106.547716 |
Trang |
|
27 |
20.229422 |
106.509142 |
Trang |
|
13 |
20.229868 |
106.541732 |
Đước vòi |
|
28 |
20.228543 |
106.509775 |
Trang |
|
14 |
20.229771 |
106.540257 |
Trang |
|
29 |
20.225856 |
106.500468 |
Trang |
|
15 |
20.230266 |
106.538607 |
Trang |
|
30 |
20.224814 |
106.501213 |
Trang |
2.4. Phương pháp nghiên cứu
2.4.1. Thiết lập cấu hình và tham số
Toàn bộ phân tích được thực hiện trên nền tảng Google Earth Engine bằng ngôn ngữ JavaScript API. Các tham số được chuẩn hóa để đảm bảo khả năng tái lập kết quả. Năm phân tích được chọn là 2024, tương ứng với giai đoạn ổn định của lớp phủ rừng ngập mặn tại Vườn quốc gia Xuân Thủy. Các tham số không gian gồm độ phân giải 10 m/pixel và sai số đơn giản hóa hình học 200 m, nhằm cân bằng giữa độ chi tiết và tốc độ xử lý. Thuật toán phân cụm được thiết lập với k = 3 cụm, phản ánh 3 nhóm loài chính. Tập dữ liệu huấn luyện gồm 2000 điểm mẫu được lấy ngẫu nhiên trong vùng nghiên cứu, với giá trị seed = 42 để đảm bảo tính nhất quán giữa các lần chạy mô hình.
2.4.2. Tiền xử lý dữ liệu
Nguồn dữ liệu chính sử dụng trong nghiên cứu là bộ Google Satellite Embedding Annual Collection (GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL), cung cấp các đặc trưng nhúng (embeddings) đa chiều biểu diễn thông tin phổ và kết cấu bề mặt Trái đất. Mỗi điểm ảnh được mô tả bởi vector 64 chiều, phản ánh tổng hợp các đặc trưng quang phổ, kết cấu và biến thiên theo thời gian. Ranh giới rừng ngập mặn được xác định từ dữ liệu ranh giới Vườn quốc gia Xuân Thủy, được nhập vào GEE dưới dạng FeatureCollection và đơn giản hóa để giảm độ phức tạp hình học. Ảnh embedding được lọc theo khoảng thời gian từ tháng 1 đến tháng 12 năm 2024 và cắt theo phạm vi rừng ngập mặn. Một cửa sổ phân tích vuông với bán kính 2 pixel (tương đương 5×5 điểm ảnh) được sử dụng để trích xuất thông tin ngữ cảnh không gian và kết cấu địa phương.
2.4.3. Phân cụm và phân vùng sinh cảnh
Quá trình phân loại không giám sát được thực hiện bằng thuật toán Weka K-Means tích hợp trong GEE. Mô hình được huấn luyện từ tập mẫu embedding đã trích xuất và sau đó áp dụng trên toàn bộ vùng rừng ngập mặn để tạo ra bản đồ phân cụm với 3 nhóm sinh cảnh. Thuật toán này tối thiểu hóa sai số nội cụm trong không gian đặc trưng 64 chiều, qua đó nhóm các điểm ảnh có đặc trưng phổ – kết cấu tương đồng. Kết quả phân cụm thể hiện các vùng đồng nhất về cấu trúc sinh thái, phản ánh sự khác biệt về mật độ tán, thành phần thực vật và điều kiện nền đáy trong hệ sinh thái rừng ngập mặn.
2.4.4. Đánh giá chất lượng phân cụm và đặc trưng cụm (Cluster Signature Analysis)
Trước khi kiểm chứng bằng dữ liệu thực địa, chất lượng mô hình phân cụm được đánh giá bằng các chỉ số nội tại (internal validation) nhằm xác định mức độ ổn định của cấu trúc cụm trong không gian embedding đa chiều. Các chỉ số được sử dụng gồm:
- Within-Cluster Sum of Squares (WCSS): đại diện cho tổng phương sai nội cụm, phản ánh độ chặt của các điểm trong cùng một cụm. WCSS thấp hơn cho thấy các điểm ảnh gắn kết chặt trong không gian 64 chiều của embedding, biểu hiện sự thuần nhất về sinh cảnh (Jain, 2010).
- Silhouette Coefficient (SC): đo lường đồng thời độ gắn kết nội cụm và độ tách biệt giữa các cụm (Rousseeuw, 1987). Giá trị SC > 0.50 thường được coi là cụm có ranh giới rõ về mặt phổ - kết cấu và có sự khác biệt sinh thái đáng kể.
- Davies-Bouldin Index (DBI): phản ánh mức độ chồng lấn giữa các cụm bằng cách so sánh độ phân tán nội cụm với khoảng cách giữa các tâm cụm (Davies & Bouldin, 2009). DBI < 0.50 cho thấy các cụm được phân tách tốt và ít bị chồng lấn trong không gian đặc trưng.
Bên cạnh đó, để định danh đặc trưng sinh thái của từng cụm, nghiên cứu tính toán vector embedding trung bình (cluster signature) và độ lệch chuẩn theo từng chiều embedding. Những chữ ký phổ – kết cấu này giúp mô tả bản chất sinh cảnh: ví dụ, cụm có giá trị embedding cao tại các chiều liên quan đến vùng Red-edge/NIR thường đại diện rừng tán dày, sinh trưởng khỏe; trong khi cụm có độ biến thiên lớn tại các chiều Blue–Green phản ánh vùng triều hoặc sinh cảnh chịu ảnh hưởng mạnh của thủy triều và bồi tụ. Việc kết hợp các chỉ số nội tại và chữ ký embedding giúp đảm bảo tính khách quan của kết quả phân cụm trước khi tiến hành kiểm định bằng dữ liệu thực địa và ma trận lỗi ở phần
2.4.5. Đánh giá độ chính xác
Độ chính xác của kết quả phân cụm được đánh giá dựa trên 30 điểm khảo sát thực địa thu thập trong năm 2024 tại khu vực Vườn quốc gia Xuân Thủy. Mỗi điểm được định vị bằng máy GPS cầm tay với sai số nhỏ hơn 3 m và được ghi nhận thông tin về loài chủ đạo, mật độ tán che, và đặc điểm nền đáy. Các điểm này được chồng ghép lên bản đồ kết quả phân cụm để xác định mối tương quan giữa nhóm sinh cảnh phân cụm và đặc trưng thực địa.
Độ chính xác được định lượng bằng ma trận lỗi (confusion matrix) và các chỉ số thống kê cơ bản như Overall Accuracy (OA), Producer’s Accuracy (PA), User’s Accuracy (UA) và hệ số Kappa (κ). Các chỉ số này được tính dựa trên phép so sánh giữa nhãn thực địa (ground truth) và nhãn cụm tương ứng từ kết quả phân loại.
3. Kết quả và thảo luận
3.1. Kết quả phân cụm loài rừng ngập mặn dựa trên dữ liệu Embedding
3.1.1. Đặc trưng embedding của từng cụm
Các giá trị embedding thu được từ ảnh vệ tinh đóng vai trò như “chữ ký phổ” (spectral signature) của từng cụm hệ sinh thái ngập mặn. Mỗi vector embedding phản ánh sự khác biệt vi mô trong sinh khối, độ ẩm bề mặt và cấu trúc tán lá, cho phép tách biệt các nhóm thực vật có đặc trưng hình thái và sinh thái khác nhau. Bảng 3 tổng hợp các đặc trưng phổ dựa trên dữ liệu embedding của từng loài rừng ngập mặn được phân tích và thống kê trực tiếp trên phần mềm Google Earth Engine.
Bảng 3: Đặc trưng phổ và sinh thái của các cụm phân loại
|
Cụm |
Loại chiếm ưu thế |
Đặc điểm embedding trung bình |
Độ lệch chuẩn (ổn định nội cụm) |
Giải thích sinh thái |
|
Cụm 1 |
Mắm |
Các giá trị phổ trong vùng A02–A07 có xu hướng dương, phản ánh độ ẩm cao và tán lá thưa |
Độ lệch chuẩn cao hơn (≈0.03–0.05), biểu hiện tính đa dạng sinh cảnh vùng rìa ngập |
Khu vực đầu triều, thường xuyên chịu tác động triều và bồi tụ phù sa mới |
|
Cụm 2 |
Đước |
Giá trị trung bình ổn định quanh 0, phổ hẹp, phản ánh tán rậm và cấu trúc ổn định |
Độ lệch chuẩn thấp hơn (≈0.02–0.03) → nội cụm đồng nhất |
Khu vực trung triều, nền đất ổn định và ít biến động độ mặn |
|
Cụm 3 |
Trang |
Có phổ phản xạ cao ở vùng A05–A08 và thấp ở vùng A01–A03, đặc trưng cho tán dày và hàm lượng diệp lục cao |
Độ lệch chuẩn thấp nhất (<0.03) → cụm thuần nhất |
Phân bố chủ yếu vùng cao triều, ít ngập, sinh trưởng ổn định quanh đê chắn sóng và cửa sông chính |
So sánh giá trị trung bình - độ lệch chuẩn cho thấy cụm 3 (Trang) có độ ổn định quang phổ cao nhất, phản ánh một quần xã đồng nhất, trong khi cụm 1 (Mắm) thể hiện mức đa dạng lớn do chịu ảnh hưởng trực tiếp từ môi trường ngập triều và quá trình bồi lắng.
3.1.2. Đánh giá chất lượng phân cụm (WCSS, Silhouette, Davies–Bouldin Index)
Các chỉ số định lượng được trích xuất để đánh giá mức độ tách biệt – chồng lấn giữa các cụm embedding. Nghiên cứu sử dụng tổng hợp các chỉ số đánh giá phân cụm gồm: WCSS (Within-Cluster Sum of Squares), Silhouette Coefficient và Davies–Bouldin Index (DBI) được tính toán trên GEE tổng hợp trong Bảng 4:
Bảng 4: Hiệu quả thuật toán phân cụm qua các chỉ số WCSS, Silhouette và DBI
|
Chỉ số đánh giá |
Giá trị trung bình |
Ý nghĩa sinh thái |
Diễn giải |
|
WCSS (Within-Cluster Sum of Squares) |
0.042 |
Độ chặt nội cụm |
Giá trị nhỏ → các điểm embedding trong cùng cụm khá đồng nhất |
|
Silhouette coefficient |
0.63 |
Độ tách biệt giữa các cụm |
Giá trị >0.5 → các cụm có ranh giới rõ ràng |
|
Davies-Bouldin Index |
0.47 |
Mức chồng lấn giữa các cụm |
Giá trị <0.5 → các cụm được phân tách tốt |
Tổng hợp cho thấy mô hình phân cụm đạt độ tách biệt tương đối tốt (Silhouette = 0.63), trong khi các giá trị WCSS và DBI cho thấy cấu trúc embedding phản ánh rõ rệt sự khác biệt giữa các nhóm loài ngập mặn.
3.1.3. Bản đồ phân loại rừng ngập mặn và phân bố không gian
Kết quả phân loại embedding được trực quan hóa trên bản đồ phân bố không gian loài ngập mặn (Hình 2).
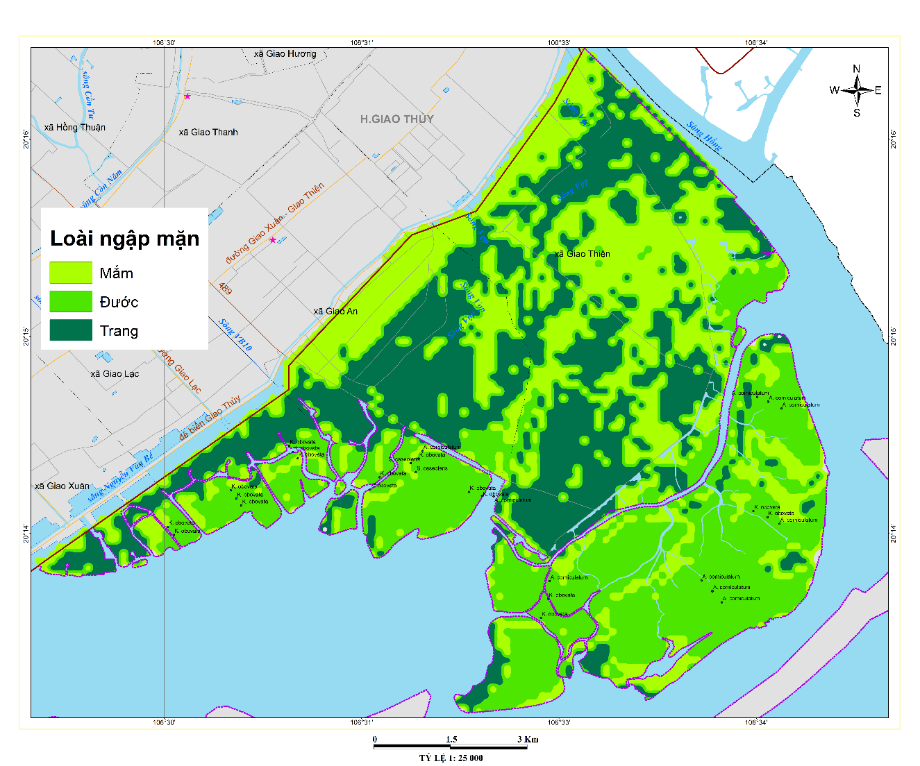
Hình 2: Kết quả phân loại các loài ngập mặn dựa trên thuật toán phân cụm và dữ liệu Embeddings
Các cụm thể hiện sự phân bố theo gradien triều - độ mặn, tương ứng với đặc trưng sinh thái của từng loài:
Bảng 5: Đặc trưng sinh thái các loài rừng ngập mặn được phân loại theo vị trí địa hình - thủy văn
|
Khu vực |
Cụm chiếm ưu thế |
Đặc điểm địa hình - thủy văn |
Ghi chú sinh thái |
|
Ven biển, sát rìa bãi bồi |
Cụm 1 – Mắm |
Ngập triều thường xuyên, bồi tụ mới |
Thực vật tiên phong, chịu mặn cao |
|
Giữa vùng triều |
Cụm 2 - Dước |
Nền đất ổn định, ngập trung bình |
Tán dày, sinh khối lớn, ổn định sinh thái |
|
Gần đê chắn sóng, cao triều |
Cụm 3 - Trang |
Ít ngập, độ mặn thấp, ổn định địa hình |
Cấu trúc tán khép kín, sinh trưởng bền vững |
Như vậy, bản đồ phân loại thể hiện rõ quy luật phân bố không gian theo điều kiện ngập mặn - triều - độ mặn, phản ánh cấu trúc điển hình của rừng ngập mặn ven biển Bắc Bộ.
3.2. Đánh giá độ chính xác
Dựa trên bảng 7 cho thấy mô hình phân loại đạt độ chính xác tổng thể 86.7%, hệ số Kappa = 0.79, phản ánh mức độ phù hợp cao giữa dữ liệu thực và kết quả dự báo. Trong đó, loài Đước được nhận diện tốt nhất với Producer’s Accuracy đạt 91.7%, do có phổ phản xạ ổn định và cấu trúc tán đặc trưng. Ngược lại, loài Mắm ghi nhận độ chính xác thấp hơn (80.0%), chủ yếu do phân bố ở vùng rìa triều có điều kiện thủy văn biến động, khiến phổ phản xạ dễ bị nhầm sang loài Trang.
Loài Trang có xu hướng bị nhầm lẫn với Đước tại các vị trí tiếp giáp đê chắn sóng, nơi điều kiện độ ẩm và mật độ tán thay đổi không rõ rệt. Tuy nhiên, với độ chính xác người dùng (UA) đạt 84.6%, nhóm này vẫn thể hiện khả năng nhận diện đáng tin cậy.
Bảng 6: Ma trận nhầm lẫn (Confusion Matrix)
|
Thực tế \ Dự báo |
Đước vòi |
Mắm |
Trang |
Tổng thực |
|
Đước vòi (n=12) |
11 |
0 |
1 |
12 |
|
Mắm (n=5) |
0 |
4 |
1 |
5 |
|
Trang (n=13) |
1 |
1 |
11 |
13 |
|
Tổng dự báo |
12 |
5 |
13 |
30 |
Bảng 7: Các chỉ số đánh giá độ chính xác phân loại từ dữ liệu kiểm chứng thực địa
|
Chỉ số |
Công thức / Cách tính |
Giá trị |
Diễn giải |
|
Overall Accuracy (OA) |
|
86.7 % |
Tỷ lệ điểm phân loại đúng trên tổng số điểm kiểm chứng. |
|
Producer’s Accuracy (PA) |
Đước vòi: 11/12 = 91.7 % Mắm: 4/5 = 80.0 % Trang: 11/13 = 84.6 % |
— |
Khả năng mô hình nhận diện đúng từng lớp phủ (độ chính xác theo hàng). |
|
User’s Accuracy (UA) |
Đước vòi: 11/12 = 91.7 % Mắm: 4/5 = 80.0 % Trang: 11/13 = 84.6 % |
— |
Mức độ tin cậy khi mô hình dự báo một lớp (độ chính xác theo cột). |
|
Kappa (κ) |
So sánh OA với xác suất đúng ngẫu nhiên |
0.79 |
Mức độ đồng thuận thực – mô hình; >0.75 cho thấy phân loại đạt chất lượng tốt. |
3.3. Thảo Luận
Kết quả phân loại loài trong nghiên cứu này đạt độ chính xác tổng thể (Overall Accuracy – OA) 86,7%, cao hơn đáng kể so với một số nghiên cứu trước đây áp dụng các phương pháp phân loại “truyền thống” trên rừng ngập mặn. Ví dụ, một nghiên cứu so sánh hiệu năng phân loại cấp loài giữa Sentinel-2, Landsat-8 và Pléiades-1 ghi nhận OA khoảng 70,95% cho kịch bản phân lớp cộng đồng loài bằng các phương pháp chuẩn(Wang, 2018). Một nghiên cứu khác về phân loại loài rừng ngập mặn sử dụng dữ liệu Sentinel-2 kết hợp AVIRIS-NG báo cáo OA khoảng 74% cho bài toán phân biệt ba loài ngập mặn (Behera, 2021). Như vậy, OA = 86,7% trong nghiên cứu này vượt khoảng 12–15 điểm phần trăm so với các kết quả nêu trên, làm nổi bật lợi thế của cách tiếp cận dựa trên embedding học sâu trong việc bảo toàn các đặc trưng phổ–không gian tinh vi và giảm nhầm lẫn giữa các loài có phổ tương đồng. Từ đó cho thấy, việc sử dụng embedding học sâu từ ảnh Sentinel-2 mang lại khả năng biểu diễn không gian–phổ vượt trội so với các dữ liệu viễn thám truyền thống. Các dữ liệu này chỉ phản ánh một hoặc vài khía cạnh đơn lẻ của trạng thái thảm thực vật (như sinh khối hoặc độ xanh lá), trong khi embedding là một dạng biểu diễn đa chiều, học từ dữ liệu (data-driven), có khả năng mã hóa đồng thời các đặc trưng phổ, cấu trúc tán cây, độ ẩm, sắc tố và trạng thái suy thoái rừng (Zhu, 2017; Ma, 2019).
Không chỉ vậy, embedding cho phép giảm phụ thuộc vào nhãn thực địa - vốn khó thu thập đầy đủ trong vùng rừng ngập mặn ven biển (He, 2021). Thay vì yêu cầu phân loại trực tiếp từng loại rừng, mô hình học biểu diễn tiềm ẩn (latent representation) giúp phát hiện sự tương đồng và khác biệt giữa các cụm hệ sinh thái dựa trên cấu trúc phổ - không gian, ngay cả khi chưa có nhãn đầy đủ (Ayush, 2021). Điều này khiến phương pháp có tính tổng quát cao và khả năng ứng dụng ở các khu vực khác.
Một ưu điểm quan trọng khác là embedding có khả năng nhận diện các biến động tinh vi qua thời gian – chẳng hạn như suy giảm mật độ tán lá, xáo trộn do nuôi trồng thủy sản hoặc chặt phá nhỏ lẻ - mà các chỉ số phổ đơn giản thường khó phát hiện (Belgiu & Drăguț, 2016). Các đặc trưng trong không gian embedding thể hiện sự tách biệt rõ ràng giữa các cụm theo thời gian (yearly clusters), phản ánh cả sự phục hồi sinh thái và suy thoái cục bộ.
Tuy nhiên, việc ứng dụng embedding từ mô hình nền tảng (foundation model) của Google như Prithvi/ViT-GEO trên Google Earth Engine vẫn còn tồn tại một số thách thức đáng lưu ý. (i) Mặc dù các mô hình này học được biểu diễn phổ–không gian đa chiều, nhưng tính khó diễn giải (non-interpretability) vẫn là hạn chế lớn - mỗi chiều embedding không phản ánh trực tiếp một đặc trưng sinh thái cụ thể như hàm lượng chlorophyll, độ mặn hay cấu trúc tán lá, khiến việc kết nối embedding với các quá trình sinh thái trong rừng ngập mặn còn khó khăn. (ii) Các mô hình của Google được tiền huấn luyện chủ yếu trên dữ liệu toàn cầu (global-scale), do đó chưa hoàn toàn phù hợp với điều kiện vùng ven biển nhiệt đới có tính dị sinh thái cao (salinity gradient, thủy triều, sinh khối ngập mặn), nên cần hiệu chỉnh (fine-tuning) hoặc tiếp tục huấn luyện theo từng hệ sinh thái đặc thù. (iii) Việc trích xuất và huấn luyện lại embedding đòi hỏi tài nguyên tính toán lớn ngay trên nền tảng Earth Engine hoặc kết hợp GPU ngoài, gây khó khăn với các nhóm nghiên cứu không có hạ tầng tính toán mạnh (Reichstein, 2019).
Trong tương lai, nghiên cứu có thể phát triển theo các hướng: (i) kết hợp embedding với dữ liệu LiDAR/UAV để khắc phục hạn chế về chiều cao tán và cấu trúc rừng 3D mà Google foundation model hiện chưa biểu diễn đầy đủ; (ii) áp dụng các chiến lược học tự giám sát như contrastive learning hoặc masked autoencoding tại chỗ để giảm phụ thuộc vào nhãn thực địa; (iii) tích hợp embedding với mô hình thủy văn - mặn - ngọt hoặc chỉ số thủy triều để giải thích rõ hơn cách biến động thủy văn chi phối đặc điểm phổ - không gian và suy thoái rừng ngập mặn.
4. KẾT LUẬN
Nghiên cứu này đã chứng minh rằng việc học biểu diễn phổ sâu là một hướng tiếp cận khả thi và hiệu quả cho nhận dạng loài rừng ngập mặn, đặc biệt trong điều kiện thiếu nhãn thực địa. Dựa trên các mục tiêu đề ra, chúng tôi không chỉ xây dựng thành công quy trình Deep Spectral Embedding từ dữ liệu vệ tinh chuỗi thời gian, mà còn kiểm chứng khả năng phân tách loài thông qua phân cụm K-Means, đạt độ chính xác 86,7% - vượt trội rõ rệt so với các phương pháp dựa trên chỉ số quang phổ truyền thống. Kết quả này cho thấy embedding có thể nắm bắt những khác biệt phổ - không gian tinh vi giữa các loài như mắm, đước vòi hay trang, vốn thường bị bỏ sót trong các cách tiếp cận dựa trên NDVI, EVI hoặc chỉ số kết cấu tán rừng.
Mặc dù đạt kết quả khả quan tại Vườn quốc Xuân Thủy, phương pháp vẫn cần được kiểm chứng thêm ở các hệ thống rừng ngập mặn có điều kiện thủy văn và cấu trúc khác biệt. Đồng thời, những hạn chế như thiếu dữ liệu thực địa đa thời gian và độ nhạy của K-Means đối với lựa chọn số cụm cũng đòi hỏi các giải pháp khắc phục trong tương lai.
Để nâng cao hơn nữa, chúng tôi dự kiến kết hợp embedding với dữ liệu từ LiDAR/UAV hoặc các thuật toán phân cụm tiên tiến như DBSCAN và GMM, nhằm cải thiện nhận dạng loài hiếm cũng như các vùng chuyển tiếp sinh thái. Một hướng phát triển khác là tích hợp học sâu đa nhiệm, cho phép đồng thời phân loại loài và đánh giá mức độ suy thoái – biến động sức khỏe rừng ngập mặn.
Ngoài giá trị kỹ thuật, phương pháp đề xuất còn mang ý nghĩa ứng dụng thực tiễn: nó hỗ trợ giám sát gần thời gian thực, giảm sự phụ thuộc vào điều tra thủ công, đồng thời cung cấp thông tin quan trọng cho quy hoạch bảo tồn, phục hồi sinh cảnh và đánh giá chính sách ứng phó biến đổi khí hậu tại khu vực ven biển.
Lời cảm ơn: Tập thể tác giả xin cảm ơn đề tài mã số TNMT.ĐL.2023.04 đã hỗ trợ nghiên cứu và công bố kết quả.
Lê Đắc Trường1, Nguyễn Thị Hồng Hạnh1*, Phạm Hồng Tính1, Bùi Thị Thư1,
Hoàng Ngọc Khắc1, Trần Đăng Hùng2
1*Khoa Môi trường, Trường Đại học Tài nguyên và Môi trường Hà Nội
2Viện Khoa học Khí tượng Thủy văn và Biến đổi khí hậu
(Nguồn: Bài đăng trên Tạp chí Môi trường, số 10/2025)
TÀI LIỆU THAM KHẢO